将 MQTT 数据传输到 Confluent
TIP
Confluent Sink 是 EMQX 企业版的功能。EMQX 企业版可以为您带来更全面的关键业务场景覆盖、更丰富的数据集成支持,更高的生产级可靠性保证以及 24/7 的全球技术支持,欢迎免费试用。
Confluent Cloud 基于 Apache Kafka,是一项弹性、可扩展、并完全托管的流式数据服务。EMQX 支持通过规则引擎与 Sink 实现与 Confluent 的数据集成,使您能够轻松将 MQTT 数据流式传输到 Confluent,实现数据的实时处理、存储和分析。
本页面主要为您介绍了 Confluent 集成的特性和优势,并指导您如何配置 Confluent Cloud 以及如何在 EMQX 中创建 Confluent 生产者 Sink。
工作原理
Confluent 数据集成是 EMQX 的开箱即用功能,能够在基于 MQTT 的物联网数据和 Confluent 强大的数据处理能力之间架起桥梁。通过内置的规则引擎组件,集成简化了两个平台之间的数据流和处理过程,无需复杂编码。
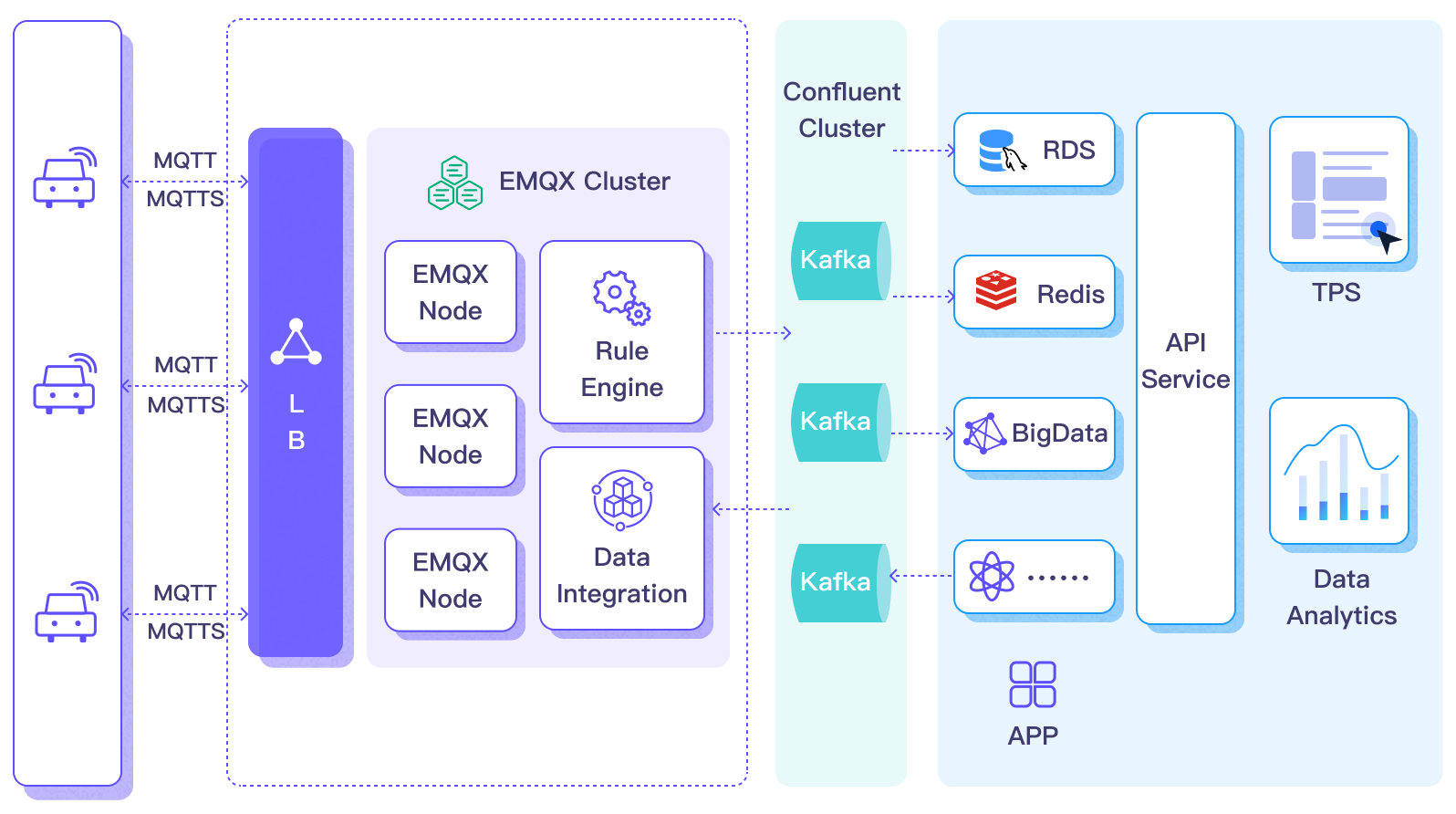
下图展示了 EMQX 与 Confluent 的数据集成在汽车物联网中的典型架构。
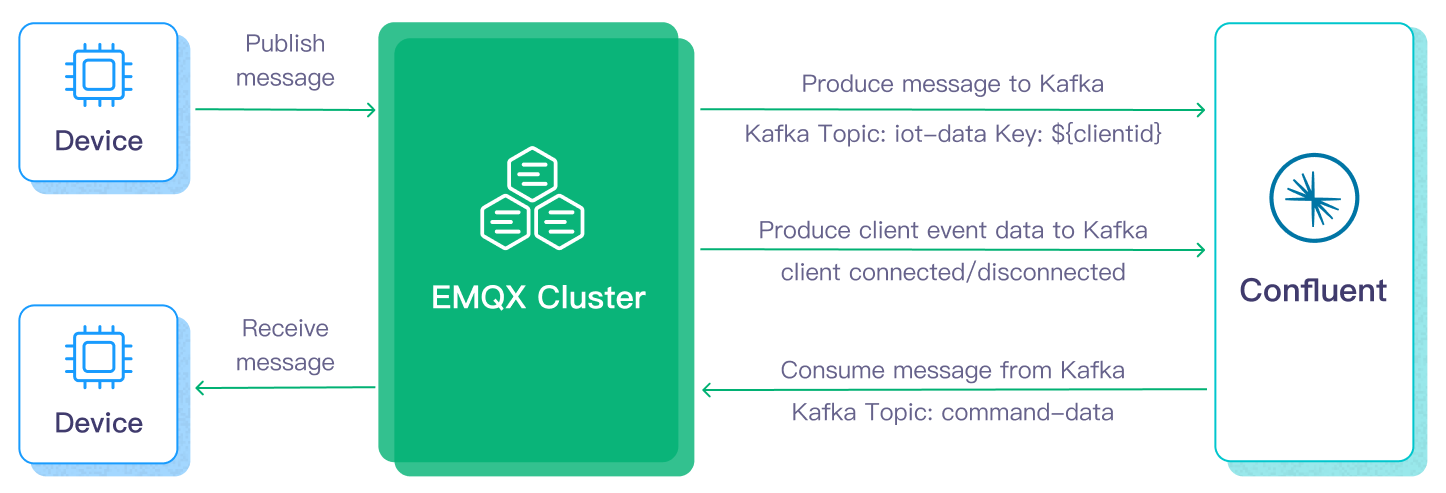
将数据流入或流出 Confluent 涉及 Confluent Sink(向 Confluent 发送消息)和 Confluent Source(从 Confluent 接收消息)。假如您创建 Confluent Sink,其工作流程如下:
- 消息发布和接收:连接车辆的物联网设备通过 MQTT 协议成功连接到 EMQX,并通过 MQTT 定期发布包含状态数据的消息。当 EMQX 收到这些消息时,它启动其规则引擎内的匹配过程。
- 消息数据处理:通过内置规则引擎与消息服务器的协同工作,这些 MQTT 消息可以根据主题匹配规则进行处理。当消息到达并通过规则引擎时,规则引擎将评估针对该消息事先定义好的处理规则。如果任何规则指定消息载荷转换,则应用这些转换,例如转换数据格式、过滤特定信息或使用额外上下文丰富载荷。
- 桥接到 Confluent:规则引擎中定义的规则触发将消息转发到 Confluent 的动作。使用 Confluent Sink 功能,MQTT 主题被映射到预定义的 Confluent 中的 Kafka 主题,所有处理过的消息和数据被写入主题中。
车辆数据被输入到 Confluent 后,您可以灵活地访问和利用这些数据:
- 您的服务可以直接与 Confluent 集成,从特定主题消费实时数据流,实现定制化的业务处理。
- 利用 Kafka Streams 进行流处理,并通过在内存中聚合和相关联车辆状态进行实时监控。
- 通过使用 Confluent Stream Designer 组件,您可以选择各种连接器将数据输出到外部系统,如 MySQL、ElasticSearch,以进行存储。
特性与优势
与 Confluent 的数据集成为您的业务带来以下特性和优势:
- 大规模消息传输的可靠性:EMQX 和 Confluent Cloud 均采用了高可靠的集群机制,可以建立稳定可靠的消息传输通道,确保大规模物联网设备消息的零丢失。两者都可以通过添加节点实现水平扩展、动态调整资源来应对突发的大规模消息,保证消息传输的可用性。
- 强大的数据处理能力:EMQX 的本地规则引擎与 Confluent Cloud 都提供了可靠的流式数据处理能力,作用在物联网数据从设备到应用的不同阶段,可以根据场景选择性地进行实时的数据过滤、格式转换、聚合分析等处理,实现更复杂的物联网消息处理流程,满足数据分析应用的需求。
- 强大的集成能力:通过 Confluent Cloud 提供的各种 Connector,可以帮助 EMQX 轻松集成其他数据库、数据仓库、数据流处理系统等,构建完整的物联网数据流程,实现数据的敏捷分析应用。
- 高吞吐量场景下的处理能力:支持同步和异步两种写入模式,您可以区分实时优先和性能优先的数据写入策略,并根据不同场景实现延迟和吞吐量之间的灵活平衡。
- 有效的主题映射:通过桥接配置,可以将众多 IoT 业务主题映射到 Kakfa 主题。EMQX 支持 MQTT 用户属性映射到 Kafka Header,并采用多种灵活的主题映射方式,包括一对一、一对多、多对多,还支持 MQTT 主题过滤器(通配符)。
这些特性增强了集成能力和灵活性,有助于您建立有效和稳健的物联网平台架构。您日益增长的物联网数据可以在稳定的网络连接下传输,并且可以进一步有效地存储和管理。
准备工作
本节描述了在 EMQX Dashboard 上配置 Confluent 集成需要完成的准备工作。
前置准备
配置 Confluent Cloud
在创建 Confluent 数据集成之前,您必须在 Confluent Cloud 控制台中创建 Confluent 集群,并使用 Confluent Cloud CLI 创建主题和 API 密钥。
创建集群
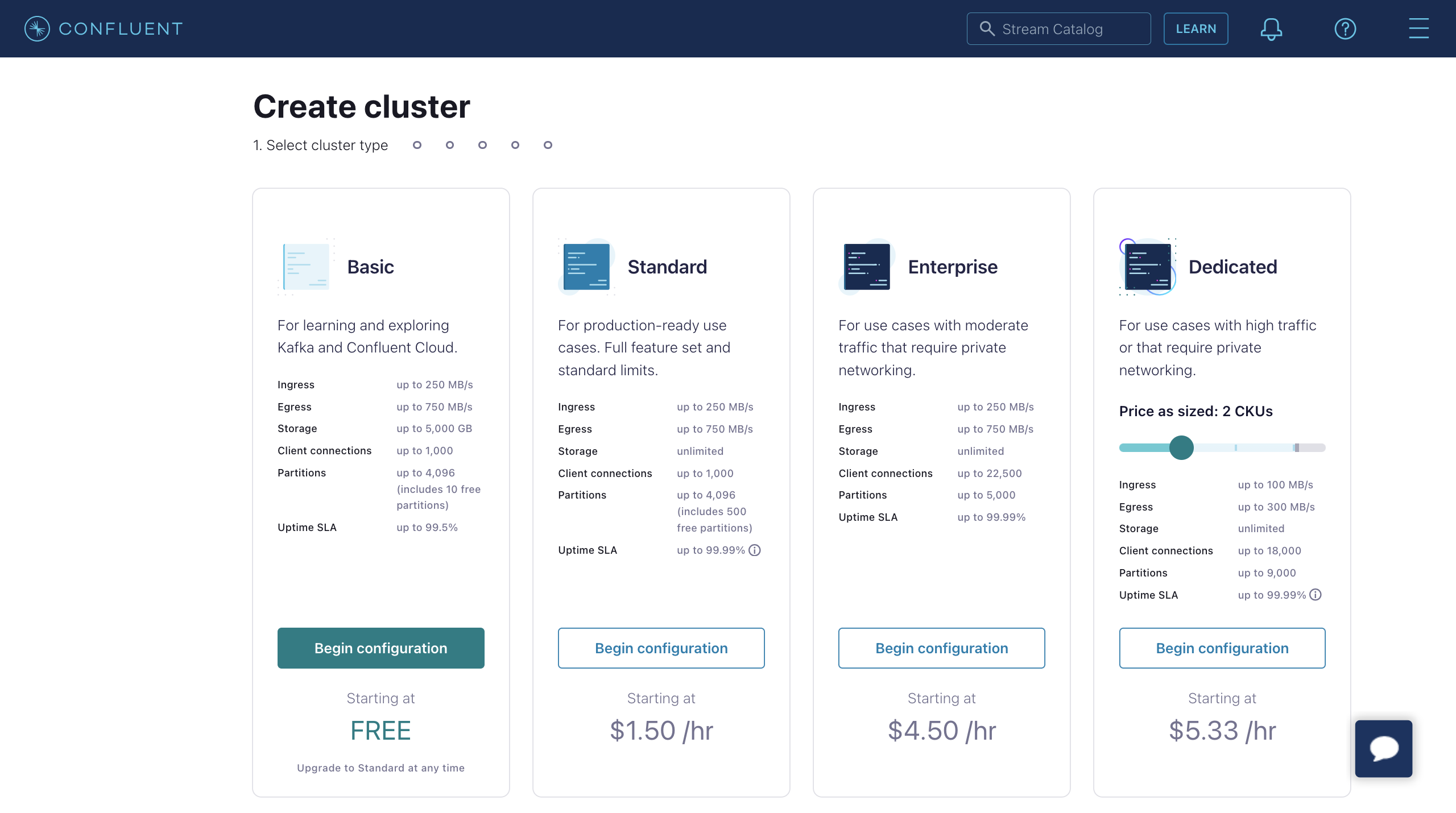
- 登录到 Confluent Cloud 控制台并创建一个集群。选择 Standard 集群作为示例,然后点击 Begin configuration。
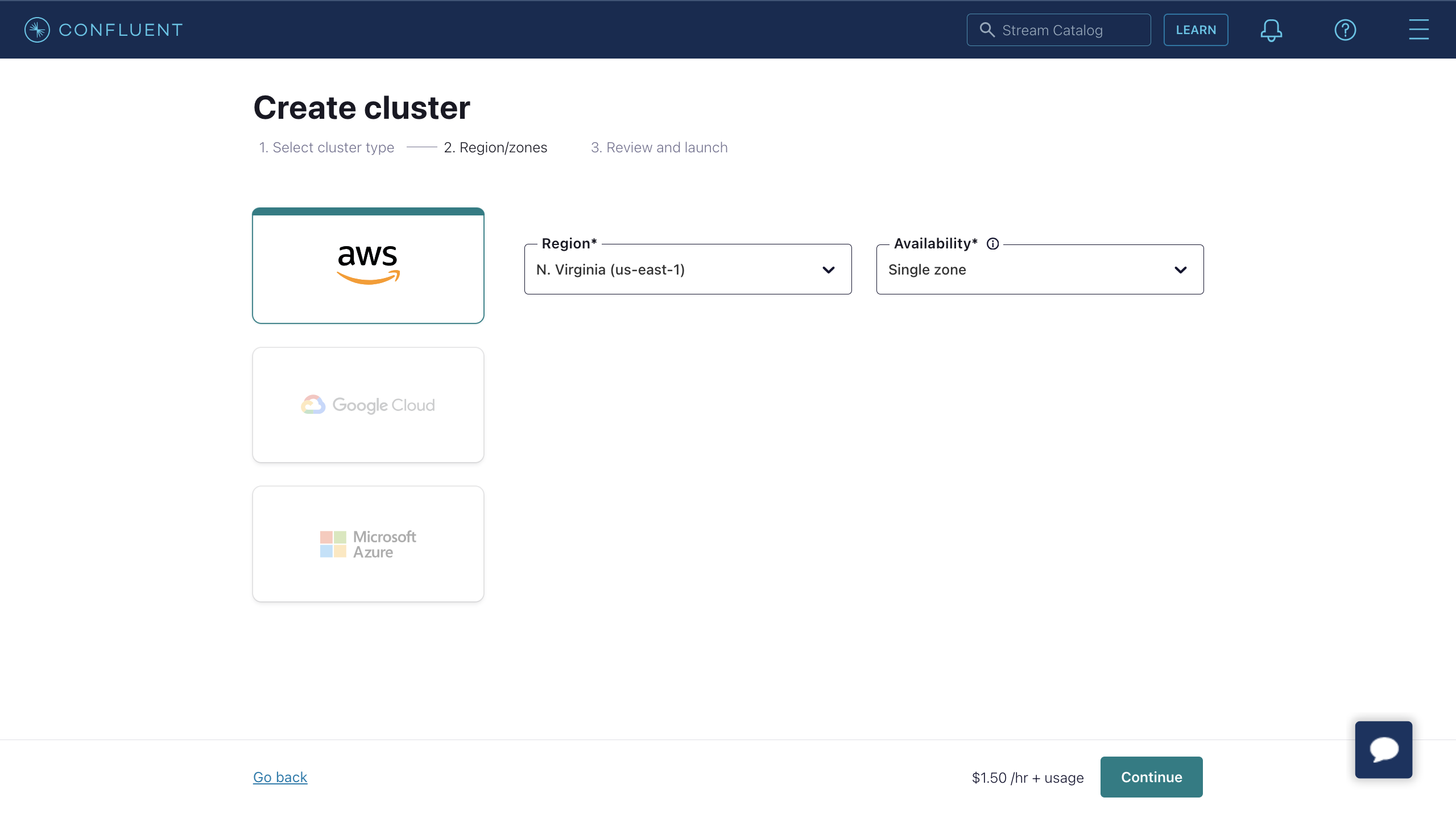
- 选择 Region/zones。确保部署区域与 Confluent Cloud 的区域匹配。然后点击 Continue。
- 输入您的集群名称,然后点击 Launch cluster。
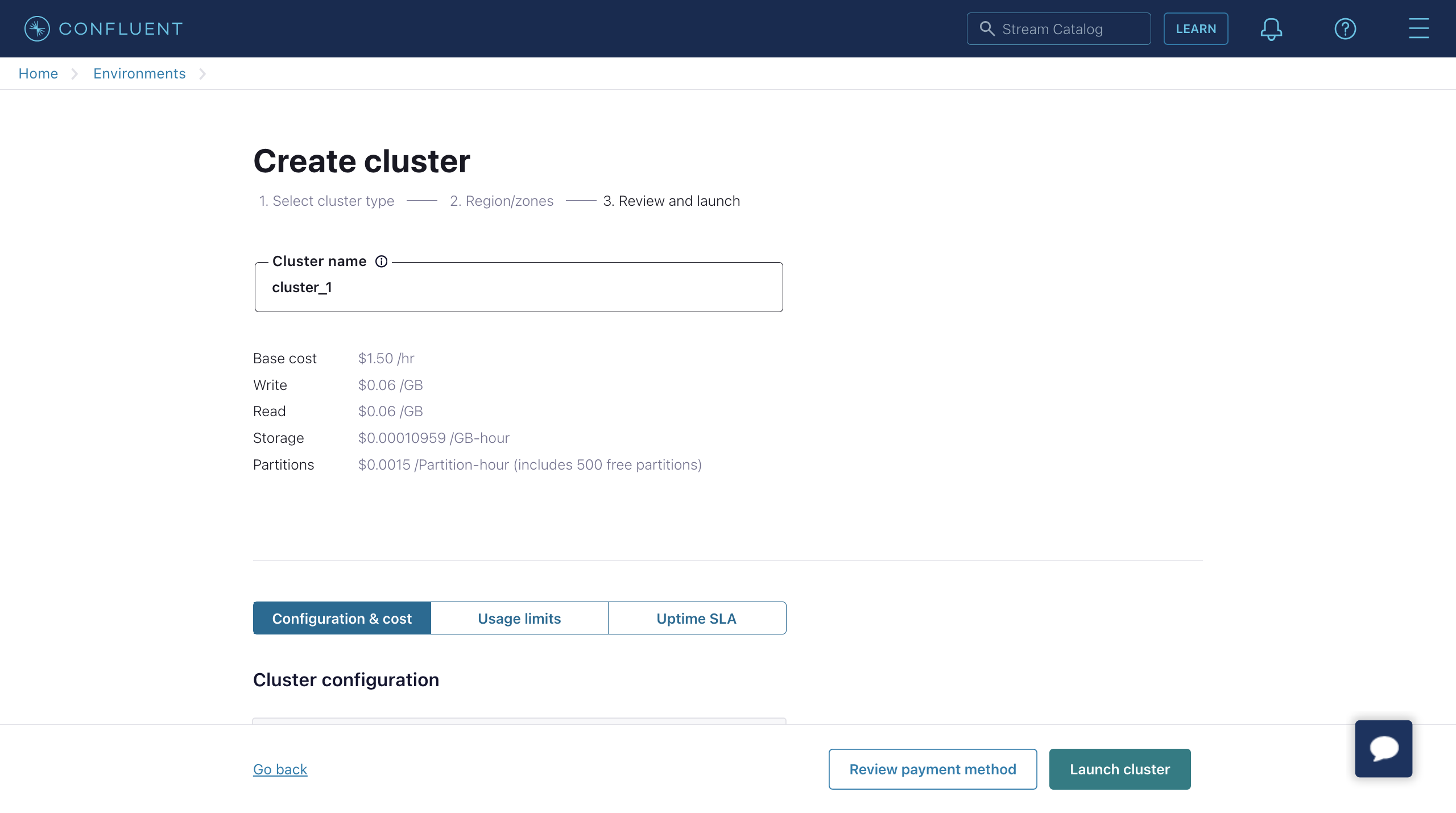
使用 Confluent Cloud CLI 创建主题和 API 密钥
现在,您已在 Confluent Cloud 中运行集群,并且可以在 Cluster Overview -> Cluster Settings 页面中获取 Bootstrap server URL。
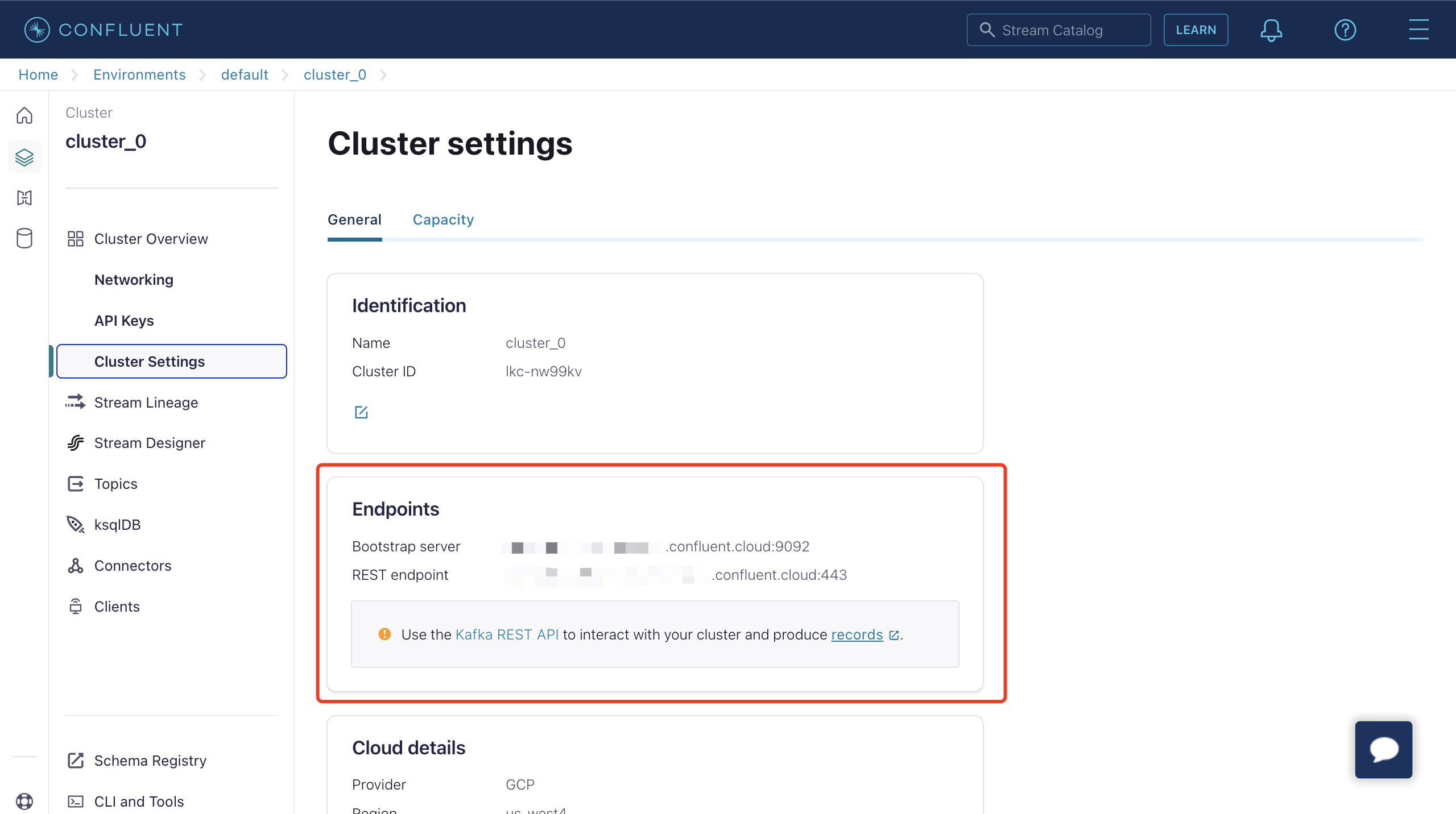
您可以使用 Confluent Cloud CLI 来管理集群。以下是使用 Confluent Cloud CLI 的基本命令。
安装 Confluent Cloud CLI
curl -sL --http1.1 https://cnfl.io/cli | sh -s -- -b /usr/local/bin如果您已经安装了,您可以使用以下命令来进行更新:
confluent update登录到您的帐户
confluent login --save选择环境
# list env
confluent environment list
# use env
confluent environment use <environment_id>选择集群
# list kafka cluster
confluent kafka cluster list
# use kafka
confluent kafka cluster use <kafka_cluster_id>使用 API 密钥和 Secret
如果您想使用现有的 API 密钥,请使用以下命令将其添加到 CLI:
confluent api-key store --resource <kafka_cluster_id>
Key: <API_KEY>
Secret: <API_SECRET>如果您没有 API 密钥和 Secret,可以使用以下命令创建:
$ confluent api-key create --resource <kafka_cluster_id>
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | YZ6R7YO6Q2WK35X7 |
| API Secret | **************************************** |
+------------+------------------------------------------------------------------+将它们添加到 CLI 后,您可以通过执行以下命令使用 API 密钥和 Secret:
confluent api-key use <API_Key> --resource <kafka_cluster_id>创建主题
您可以使用以下命令创建一个名为 testtopic-in 的主题:
confluent kafka topic create testtopic-in您可以使用以下命令检查主题列表:
confluent kafka topic list向主题生成消息
您可以使用以下命令创建生产者。启动生产者后,输入一条消息并按 Enter 键。消息将被生成到相应的主题中。
confluent kafka topic produce testtopic-in从主题消费消息
您可以使用以下命令创建消费者。它将输出相应主题中的所有消息。
confluent kafka topic consume -b testtopic-in创建连接器
在添加 Confluent Sink 前,您需要创建 Confluent 生产者连接器,以便 EMQX 与 Confluent Cloud 建立连接。
- 进入 EMQX Dashboard,并点击 集成 -> 连接器。
- 点击页面右上角的创建,在连接器选择页面,选择 Confluent 生产者,点击下一步。
- 输入名称与描述,例如
my-confluent,名称用于 Confluent Sink 关联选择连接器,要求在集群中唯一。 - 配置连接到 Confluent Cloud 所需的参数:
- 主机列表:对应 Confluent 集群设置页面中的 Endpoints 信息。
- 用户名与密码:填入您之前用 Confluent Cloud CLI 创建的 API 密钥和 Secret。
- 将其他选项保留为默认值,或根据您的业务需求进行配置。
- 点击创建按钮完成连接器的创建。
创建成功后,连接器将自动连接到 Confluent Cloud。接下来,我们将基于此连接器创建一条规则,将数据转发到连接器所配置的 Confluent 集群中。
创建 Confluent 生产者 Sink 规则
本节演示了如何在 EMQX 中创建规则,以处理来自源 MQTT 主题 t/# 的消息,并通过配置的 Confluent Sink 发送处理结果以产生数据到 Confluent 的 testtopic-in 主题。
进入 EMQX Dashboard,并点击 集成 -> 规则。
点击页面右上角的创建。
输入一个规则 ID,例如
my_rule。如果您想将主题
t/#的 MQTT 消息转发到 Confluent,可以在 SQL 编辑器 中输入以下语句。注意:如果您想指定自己的 SQL 语法,请确保在
SELECT部分包含了 Sink 所需的所有字段。sqlSELECT * FROM "t/#"注意:如果您是初学者,可以点击 SQL 示例 和 启用测试 学习和测试 SQL 规则。
点击 + 添加动作 按钮来定义规则触发的动作。从动作类型下拉列表中选择 Confluent 生产者,保持动作下拉框为默认的
创建动作选项,您也可以从动作下拉框中选择一个之前已经创建好的 Confluent 生产者动作。此处我们创建一个全新的 Sink 并添加到规则中。在下方的表单中输入 Sink 的名称与描述。
在连接器下拉框中选择刚刚创建的
my-confluent连接器。您也可以点击下拉框旁边的创建按钮,在弹出框中快捷创建新的连接器,所需的配置参数按照参照创建连接器。配置 Sink 的数据发送方式,包括:
Kafka 主题名称:输入
testtopic-in。注意:此处不支持变量。Kafka Headers:输入与 Kafka 消息相关的元数据或上下文信息(可选)。占位符的值必须是一个对象。您可以从 Kafka Headers 值编码类型 下拉列表中选择 Header 的值编码类型。您还可以通过点击 添加 来添加更多键值对。
消息的键:Kafka 消息键。在此输入一个字符串,可以是纯字符串或包含占位符 (${var}) 的字符串。
消息的值:Kafka 消息值。在此输入一个字符串,可以是纯字符串或包含占位符 (${var}) 的字符串。
分区选择策略:选择生产者向 Kafka 分区分发消息的方式。
压缩:指定是否使用压缩算法压缩/解压 Kafka 消息中的记录。
高级设置(可选):请参阅 高级配置。
点击 创建 按钮完成 Sink 的创建,创建成功后页面将回到创建规则,新的 Sink 将添加到规则动作中。
点击 创建 按钮完成整个规则创建。
现在您已成功创建了规则,你可以点击集成 -> 规则页面看到新建的规则,同时在动作(Sink) 标签页看到新建的 Confluent 生产者 Sink。
您也可以点击 集成 -> Flow 设计器 查看拓扑,通过拓扑可以直观的看到,主题 t/# 下的消息在经过规则 my_rule 解析后被发送并保存到 Confluent。
测试 Confluent 生产者 Sink 规则
为了测试 Confluent 生产者规则是否按照您的预期工作,您可以使用 MQTTX 来模拟客户端向 EMQX 发布 MQTT 消息。
使用 MQTTX 向主题
t/1发送消息:bashmqttx pub -i emqx_c -t t/1 -m '{ "msg": "Hello Confluent" }'在 Sink 页面上点击 Sink 的名称查看统计信息。检查 Sink 的运行状态,应该有一个新的传入消息和一个新的传出消息。
使用以下 Confluent 命令检查消息是否被写入
testtopic-in主题:bashconfluent kafka topic consume -b testtopic-in
高级配置
本节描述了一些高级配置选项,这些选项可以优化您的连接器与 Sink/Source 性能,并根据您的特定场景定制操作,在创建对应的对象时,您可以展开 高级设置 并根据业务需求配置以下设置。
连接器配置
| 字段 | 描述 | 推荐值 |
|---|---|---|
| 连接超时 | 等待 TCP 连接建立的最大时间,包括启用时的认证时间。 | 5秒 |
| 启动超时时间 | 确定连接器在回应资源创建请求之前等待自动启动的资源达到健康状态的最长时间间隔(以秒为单位)。此设置有助于确保连接器在验证连接的资源(例如 Confluent 集群)完全运行并准备好处理数据事务之前不会执行操作。 | 5秒 |
| 健康检查间隔 | 检查连接器运行状态的时间间隔。 | 15秒 |
| 元数据刷新最小间隔 | 客户端在刷新 Kafka 代理和主题元数据之前必须等待的最短时间间隔。将此值设置得太小可能会不必要地增加 Kafka 服务器的负载。 | 3秒 |
| 元数据请求超时 | 连接器从 Kafka 请求元数据时的最大等待时长。 | 5秒 |
| Socket 发送/收包缓存大小 | 管理 TCP socket 发送/收包缓存大小以优化网络传输性能。 | 1024KB |
| 是否关闭延迟发送 | 选择是否让系统内核立即或延迟发送 TCP socket。打开切换开关即关闭延迟发送,可以让系统内核立即发送,否则当需要发送的内容很少时,可能会有一定延迟(默认 40 毫秒)。 | 关闭 |
| TCP Keepalive | 此配置为连接器启用 TCP 保活机制,以维护持续连接的有效性,防止由长时间不活动导致的连接中断。该值应以逗号分隔的三个数字格式提供,格式为 Idle, Interval, Probes:Idle:服务器发起保活探测前连接必须保持空闲的秒数。Linux 上的默认值是 7200 秒。 Interval:每个 TCP 保活探测之间的秒数。Linux 上的默认值是 75 秒。 Probes:在将连接视为关闭之前,发送的最大 TCP 保活探测次数(如果对端没有响应)。Linux 上的默认值是 9 次探测。 例如,如果您将值设置为 240,30,5,则意味着在 240 秒的空闲时间后将发送 TCP 保活探测,随后每 30 秒发送一次探测。如果连续 5 次探测尝试没有响应,连接将被标记为关闭。 | none |
Confluent 生产者 Sink 配置
| 字段 | 描述 | 推荐值 |
|---|---|---|
| 健康检查间隔 | 检查 Sink 运行状态的时间间隔。 | 15秒 |
| 最大批量字节数 | 在 Kafka 批次中收集消息的最大字节大小。通常,Kafka 代理的默认批量大小限制为 1 MB。然而,EMQX 的默认值故意设置得略低于 1 MB,以考虑 Kafka 消息编码开销,特别是当单个消息非常小的时候。如果单个消息超过此限制,它仍然会作为单独的批次发送。 | 896KB |
| Kafka 确认数量 | Kafka 分区 leader 在向 EMQX Confluent 生产者 Sink 发送确认之前,需要从其 follower 等待的确认:all_isr:需要来自所有同步副本的确认。leader_only:仅需要来自分区 leader 的确认。none:不需要来自 Kafka 的确认。 | all_isr |
| 分区数量刷新间隔 | Kafka 生产者检测到分区数量增加的时间间隔。一旦 Kafka 的分区数量增加,EMQX 将根据指定的 partition_strategy 将这些新发现的分区纳入其消息分发过程。 | 60秒 |
| 飞行窗口(生产者) | Kafka 生产者(每个分区)在从 Kafka 收到确认之前允许发送的最大批次数。更大的值通常意味着更好的吞吐量。然而,当这个值大于 1 时,可能存在消息重排序的风险。 此选项控制在途中未确认消息的数量,有效平衡负载,以防系统过载。 | 10 |
| 请求模式 | 允许您选择异步或同步请求模式,以根据不同需求优化消息传输。在异步模式下,写入 Kafka 不会阻塞 MQTT 消息发布过程。然而,这可能导致客户端在消息到达 Kafka 之前就接收到消息。 | 异步 |
| 同步查询超时时间 | 在同步查询模式下,建立等待确认的最大等待时间。这确保及时完成消息传输,避免长时间等待。 仅当 Sink 的请求模式配置为 同步 时适用。 | 5秒 |
| 缓存模式 | 定义在发送之前是否将消息存储在缓冲区中。内存缓冲可以提高传输速度。memory:消息在内存中缓冲。如果 EMQX 节点重启,它们将会丢失。disk:消息在磁盘上缓冲,确保它们可以在 EMQX 节点重启后存活。hybrid:消息最初在内存中缓冲。当它们达到一定限制时(具体请参见 segment_bytes 配置),它们将逐渐转移到磁盘上。与内存模式类似,如果 EMQX 节点重启,消息将会丢失。 | memory |
| Kafka 分区缓存上限 | 每个 Kafka 分区允许的最大缓存大小(以字节为单位)。达到此限制时,将丢弃较旧的消息以为新消息腾出缓存空间。 此选项有助于平衡内存使用和性能。 | 2GB |
| 缓存文件大小 | 当缓存模式配置为 disk 或 hybrid 时适用。它控制用于存储消息的分段文件的大小,影响磁盘存储的优化程度。 | 100MB |
| 内存过载保护 | 当缓存模式配置为 memory 时适用。当 EMQX 遇到高内存压力时,将自动丢弃较旧的缓存消息。它有助于防止因过度内存使用而导致的系统不稳定,确保系统可靠性。注意:高内存使用的阈值定义在配置参数 sysmon.os.sysmem_high_watermark 中。此配置仅在 Linux 系统上有效。 | 禁用 |
更多信息
EMQX 提供了大量关于与 Confluent/Kafka 的数据集成的学习资源。请查看以下链接以了解更多信息:
博客:
- 使用 MQTT 和 Kafka 三分钟构建车联网流数据管道
- MQTT 与 Kafka |物联网消息与流数据集成实践
- MQTT Performance Benchmark Testing: EMQX-Kafka Integration
基准测试报告: