Ingest MQTT Data into Apache IoTDB
TIP
The Apache IoTDB data integration is an EMQX Enterprise Edition feature. EMQX Enterprise Edition provides comprehensive coverage of key business scenarios, rich data integration, product-level reliability, and 24/7 global technical support. Experience the benefits of this enterprise-ready MQTT messaging platform today.
Apache IoTDB is a high-performance and scalable time series database designed to handle massive amounts of time series data generated by various IoT devices and systems. EMQX supports data integration with Apache IoTDB, enabling you to seamlessly forward data via the lightweight MQTT protocol to Apache IoTDB using their REST API V2. The data integration ensures a single-directional flow. MQTT messages from EMQX are written into the IoTDB database, leveraging both EMQX's exceptional real-time data ingestion capabilities and IoTDB's specialized time-series data storage and query performance. This powerful combination is a solid foundation for businesses looking to manage their IoT data effectively.
This page provides a comprehensive introduction to the data integration between EMQX and Apache IoTDB with practical instructions on creating and validating the data integration.
How It Works
The Apache IoTDB data integration is an out-of-the-box feature in EMQX designed to bridge the gap between raw MQTT-based time series data and IoTDB's powerful data storage capabilities. With a built-in rule engine component, the integration simplifies the process of ingesting data from EMQX to IoTDB for storage and query, eliminating the need for complex coding.
The diagram below illustrates a typical architecture of data integration between EMQX and IoTDB.
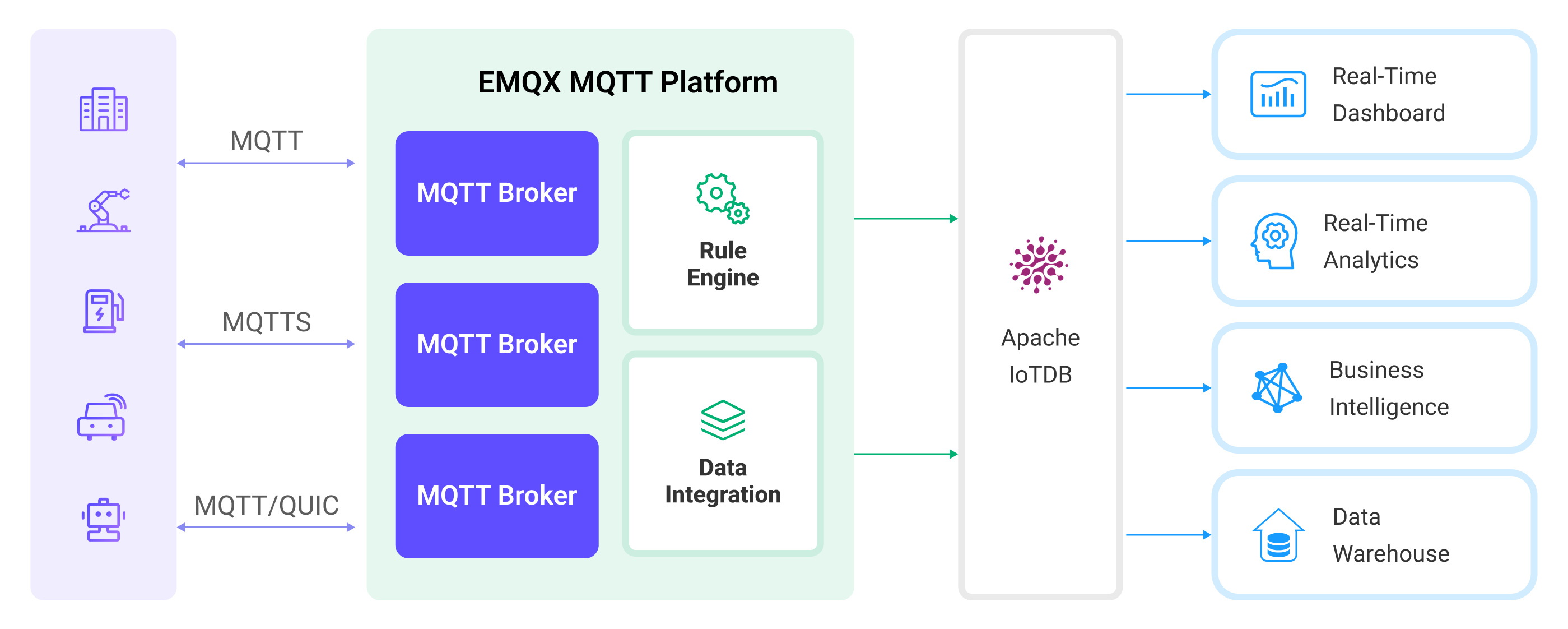
The workflow of the data integration is as follows:
- Message publication and reception: Devices, whether they are part of connected vehicles, IIoT systems, or energy management platforms, establish successful connections to EMQX through the MQTT protocol and send messages via MQTT based on their operational states, readings, or triggered events. When EMQX receives these messages, it initiates the matching process within its rules engine.
- Message data processing: When a message arrives, it passes through the rule engine and is then processed by the rule defined in EMQX. The rules, based on predefined criteria, determine which messages need to be routed to IoTDB. If any rules specify payload transformations, those transformations are applied, such as converting data formats, filtering out specific information, or enriching the payload with additional context.
- Data buffering: EMQX provides an in-memory message buffer to prevent data loss when the IoTDB is unavailable. Data is temporarily held in the buffer, and may be offloaded to disk to prevent memory overload. Note that data is not preserved if the data integration or the EMQX node is restarted.
- Data ingestion into IoTDB: Once the rule engine identifies a message for IoTDB storage, it triggers an action of forwarding the messages to IoTDB. Processed data will be seamlessly written into the IoTDB in a time series manner.
- Data Storage and Utilization: With the data now stored in IoTDB, businesses can harness its querying power for various use cases. For instance, in the realm of connected vehicles, this stored data can inform fleet management systems about vehicle health, optimize route planning based on real-time metrics, or track assets. Similarly, in IIoT settings, the data might be used to monitor machinery health, forecast maintenance, or optimize production schedules.
Features and Benefits
The data integration with IoTDB offers a range of features and benefits tailored to ensure effective data handling and storage:
Efficient Data Collection
By integrating EMQX with IoTDB, IoT time-series data can be efficiently collected through the lightweight MQTT messaging protocol from IoT devices with limited resources and ingested into the database, ensuring reliable and efficient data collection.
Flexible Data Transformation
EMQX provides a powerful SQL-based Rule Engine, allowing organizations to pre-process data before storing it in IoTDB. It supports various data transformation mechanisms, such as filtering, routing, aggregation, and enrichment, enabling organizations to shape the data according to their needs.
Scalability and High Throughput
EMQX is architected for horizontal scalability, effortlessly managing the surging message traffic generated by an ever-expanding fleet of IoT devices. This solution effortlessly adapts to expanding data volumes and supports high-concurrency access. As a result, IoT time-series workloads can effortlessly manage the increasing requirements of data ingestion, storage, and processing as IoT deployments scale to unprecedented levels.
Optimized Time-Series Storage:
IoTDB provides optimized storage for time-stamped data. It leverages time-partitioning, compression, and data retention policies to efficiently store and manage large volumes of time-series data. This ensures a minimal storage footprint while maintaining high performance, which is essential for IoT workloads that generate massive amounts of time-series data.
Fast and Complex Querying
IoTDB has rich query semantics, supporting time alignment for timeseries data accross devices and sensors, computation in timeseries field (frequency domain transformation) and rich aggregation function support in time dimension. It also deeply integrates with Apache Hadoop, Spark and Flink, providing more powerful analytics capabilities. EMQX seamlessly integrates with IoTDB, providing a unified solution for storing and analyzing MQTT data.
Before You Start
This section describes the preparations you must complete before creating the Apache IoTDB data integration in EMQX Dashboard.
Prerequisites
- Knowledge about EMQX data integration rules
- Knowledge about data integration
Start an Apache IoTDB Server
This section introduces how to start an Apache IoTDB server using Docker. Make sure to have enable_rest_service=true in your IoTDB's configuration.
Run the following command to start an Apache IoTDB server with its REST interface enabled:
docker run -d --name iotdb-service \
--hostname iotdb-service \
-p 6667:6667 \
-p 18080:18080 \
-e enable_rest_service=true \
-e cn_internal_address=iotdb-service \
-e cn_target_config_node_list=iotdb-service:10710 \
-e cn_internal_port=10710 \
-e cn_consensus_port=10720 \
-e dn_rpc_address=iotdb-service \
-e dn_internal_address=iotdb-service \
-e dn_target_config_node_list=iotdb-service:10710 \
-e dn_mpp_data_exchange_port=10740 \
-e dn_schema_region_consensus_port=10750 \
-e dn_data_region_consensus_port=10760 \
-e dn_rpc_port=6667 \
apache/iotdb:1.1.0-standaloneYou can find more information about running IoTDB in Docker on Docker Hub.
Create a Connector
To create the Apache IoTDB data integration, you need to create a Connector to connect the Apache IoTDB Sink to the Apache IoTDB server.
- Go to the EMQX Dashboard and click on Integrations -> Connectors.
- Click Create in the top right corner of the page.
- On the Create Connector page, select Apache IoTDB as the Connector type, and click Next.
- Enter the name and description of the Connector. The name can be a combination of uppercase/lowercase letters or numbers, for example,
my_iotdb. - Enter
http://localhost:18080in the IoTDB REST Service Base URL. - Enter the username and password for the Connector to access the Apache IoTDB server.
- Leave the other options as default. For the configuration of Advanced Settings (optional): See Advanced Configurations.
- Before clicking Create, you can click Test Connectivity to test that the Connector can connect to the Apache IoTDB.
- Click Create to complete the creation of the Connector. In the pop-up dialogue, you can click Back to Connector List or click Create Rule to continue to create a rule and a Sink for specifying the data to be written into Apache IoTDB. For detailed steps, see Create a Rule and Apache IoTDB Sink.
Create a Rule with Apache IoTDB Sink
This section demonstrates how to create a rule in EMQX to process messages from the source MQTT topic root/# and send the processed results through the configured Apache IoTDB Sink to store the time series data to Apache IoTDB.
Go to the EMQX Dashboard, and click Integration -> Rules.
Click Create on the top right corner of the page.
Enter a rule ID, for example,
my_rule.Enter the following statement in the SQL editor, which will forward the MQTT messages matching the topic pattern
root/#:sqlSELECT * FROM "root/#"TIP
If you are a beginner, you can click SQL Examples and Enable Test to learn and test SQL rules.
Click the Add Action button to define an action to be triggered by the rule. Select
Apache IoTDBfrom the Type of Action dropdown list. With this action, EMQX will send the data processed by the rule to Apache IoTDB.Keep the Action dropdown box with the value
Create Action. Or, you can also select an Apache IoTDB Sink previously created. In this demonstration, you create a new Sink and add it to the rule.Enter the name and description of the Sink.
Select the Connector
my_iotdbyou just created from the Connector dropdown box. You can also create a new Connector by clicking the button next to the dropdown box. For the configuration parameters, see Create a Connector.Configure the following information for the Sink:
Device ID (optional): Enter a specific device ID to be used as the device name for forwarding and inserting timeseries data into the IoTDB instance.
TIP
If left empty, the device ID can still be specified in the published message or configured within the rule. For example, if you publish a JSON-encoded message with a
device_idfield, the value of that field will determine the output device ID. To extract this information using the rule engine, you can use SQL similar to the following:sqlSELECT payload, `my_device` as payload.device_idHowever, the fixed device ID configured in this field takes precedence over any previously mentioned methods.
- Align Timeseries: Disabled by default. Once enabled, the timestamp columns of a group of aligned timeseries are stored only once in IoTDB, rather than duplicating them for each individual timeseries within the group. For more information, see Aligned timeseries.
Configure the Write Data to specify the ways to generate IoTDB data from MQTT messages. Due to historical reasons, you can select either of the following methods:
Payload-Described
In this approach, you should leave the Write Data field empty and include the required contextual information in the MQTT message in the
SELECTpart of the rule. For example, the client is sending a message with the payload in JSON format as follows:json{ "measurement": "temp", "data_type": "FLOAT", "value": "32.67", "device_id": "root.sg27" // optional }You can use the following rule to present the fields
measurement,data_typeandvalue.sqlSELECT payload.measurement, payload.data_type, payload.value, clientid as payload.device_id FROM "root/#"If the payload is structured differently, you can use the rule to rewrite its structure like the following:
sqlSELECT payload.measurement, payload.dtype as payload.data_type, payload.val as payload.value FROM "root/#"Template-Described
With this approach, you can define a template in the Write Data section, including as many items as needed, each with the required contextual information per row. When this template is provided, the system will generate IoTDB data by applying it to the MQTT message. The template for writing data supports batch setting via CSV file. For details, refer to Batch Setting.
For example, consider this template:
Timestamp Measurement Data Type Value index INT32 ${index} temperature FLOAT ${temp} TIP
Each column supports placeholder syntax to fill it with variables.
If the Timestamp is omitted, it will be automatically filled with the current system time in milliseconds.
Then, your MQTT message can be structured as follows:
json{ "index": "42", "temp": "32.67" }
Advanced settings (optional): See Advanced Configurations.
Before clicking Create, you can click Test Connectivity to test if the Sink can be connected to the Apache IoTDB server.
Click Create to complete the Sink creation. Back on the Create Rule page, you will see the new Sink appear under the Action Outputs tab.
On the Create Rule page, verify the configured information. Click the Create button to generate the rule.
Now you have successfully created the rule and you can see the new rule appear on the Rule page. Click the Actions(Sink) tab, you can see the new Apache IoTDB Sink.
You can click Integration -> Flow Designer to view the topology. It can be seen that the messages under the topic root/# are forwarded to Apache IoTDB after parsing by the rule my_rule.
Batch Setting
In Apache IoTDB, writing hundreds of data entries simultaneously can be challenging when configuring on the Dashboard. To address this issue, EMQX offers a functionality for batch setting data writes.
When configuring Write Data, you can use the batch setting feature to import fields for insertion operations from a CSV file.
Click the Batch Setting button in the Write Data table to open the Import Batch Setting popup.
Follow the instructions to download the batch setting template file, then fill in the data writing configuration in the template file. The default template file content is as follows:
Timestamp Measurement Data Type Value Remarks (Optional) now temp FLOAT ${payload.temp} Fields, values, and data types are mandatory. Available data type options include BOOLEAN, INT32, INT64, FLOAT, DOUBLE, TEXT now hum FLOAT ${payload.hum} now status BOOLEAN ${payload.status} now clientid TEXT ${clientid} - Timestamp: Supports placeholders in ${var} format, requiring timestamp format. You can also use the following special characters to insert system time:
- now: Current millisecond timestamp
- now_ms: Current millisecond timestamp
- now_us: Current microsecond timestamp
- now_ns: Current nanosecond timestamp
- Measurement: Field name, supports constants or placeholders in ${var} format.
- Data Type: Data type, with options including BOOLEAN, INT32, INT64, FLOAT, DOUBLE, TEXT.
- Value: The data value to be written, supports constants or placeholders in ${var} format, and must match the data type.
- Remarks: Used only for notes within the CSV file, cannot be imported into EMQX.
Note that only CSV files under 1M and with data not exceeding 2000 lines are supported.
- Timestamp: Supports placeholders in ${var} format, requiring timestamp format. You can also use the following special characters to insert system time:
Save the filled template file and upload it to the Import Batch Setting popup, then click Import to complete the batch setting.
After importing, you can further adjust the data in the Write Data table.
Test the Rule
You can use the built-in WebSocket client in the EMQX dashboard to test your Apache IoT Sink and rule.
Click Diagnose -> WebSocket Client in the left navigation menu of the Dashboard.
Fill in the connection information for the current EMQX instance.
- If you run EMQX locally, you can use the default value.
- If you have changed EMQX's default configuration. For example, the configuration change on authentication can require you to type in a username and password.
Click Connect to connect the client to the EMQX instance.
Scroll down to the publish area. Specify the device id in the message and type the following:
Topic:
root/testPayload:
json{ "measurement": "temp", "data_type": "FLOAT", "value": "37.6", "device_id": "root.sg27" }QoS:
2
Click Publish to send the message.
Publish another message with the device id specified in the topic:
Topic:
root/sg27TIP
If your topic does not start with
rootit will automatically be prefixed. For example, if you publish the message totest/sg27the resulting device name will beroot.test.sg27. Make sure your rule and topic are configured correctly, so it forwards messages from that topic to the Sink.Payload:
json
{ "measurement": "temp", "data_type": "FLOAT", "value": "37.6" }
- **QoS**: `2`Click Publish to send the message.
If the Sink and rule are successfully created, the messages should have been published to the specified time series table in the Apache IoTDB server.
Check the messages by using IoTDB's command line interface. If you're using it from docker as shown above, you can connect to the server by using the following command from your terminal:
shell$ docker exec -ti iotdb-service /iotdb/sbin/start-cli.sh -h iotdb-serviceIn the console, continue to type the following:
sqlIoTDB> select * from root.sg27You should see the data printed as follows:
+------------------------+--------------+ | Time|root.sg27.temp| +------------------------+--------------+ |2023-05-05T14:26:44.743Z| 37.6| |2023-05-05T14:27:44.743Z| 36.6| +------------------------+--------------+
Advanced Configurations
This section describes some advanced configuration options that can optimize the performance of your Connector and customize the operation based on your specific scenarios. When creating the Connector, you can unfold the Advanced Settings and configure the following settings according to your business needs.
| Fields | Descriptions | Recommended Values |
|---|---|---|
| HTTP Pipelining | Specifies the number of HTTP requests that can be sent to the server in a continuous sequence without waiting for individual responses. This option takes a positive integer value that represents the maximum number of HTTP requests that will be pipelined. When set to 1, it indicates a traditional request-response model where each HTTP request will be sent, and then the client will wait for a server response before sending the next request. Higher values enable more efficient use of network resources by allowing multiple requests to be sent in a batch, reducing the round-trip time. | 100 |
| Pool Type | Defines the algorithmic strategy used for managing and distributing connections in the Connector between EMQX and Apache IoTDB. When set to random, connections to the Apache IoTDB server will be randomly selected from the available connection pool. This option provides a simple, balanced distribution.When set to hash, a hashing algorithm is used to consistently map requests to connections in the pool. This type is often used in scenarios where a more deterministic distribution of requests is required, such as load balancing based on client identifiers or topic names.Note: Choosing the appropriate pool type depends on your specific use case and the distribution characteristics that you aim to achieve. | random |
| Connection Pool Size | Specifies the number of concurrent connections that can be maintained in the connection pool when interfacing with the Apache IoTDB service. This option helps in managing the application's scalability and performance by limiting or increasing the number of active connections between EMQX and Apache IoTDB. Note: Setting an appropriate connection pool size depends on various factors such as system resources, network latency, and the specific workload of your application. Too large a pool size may lead to resource exhaustion, while too small a size may limit throughput. | 8 |
| Connect Timeout | Specifies the maximum amount of time, in seconds, that the EMQX will wait while attempting to establish a connection with the Apache IoTDB HTTP server. Note: A carefully chosen timeout setting is crucial for balancing system performance and resource utilization. It is advisable to test the system under various network conditions to find the optimal timeout value for your specific use case. | 15 |
| HTTP Request Max Retries | Specifies the maximum number of times an HTTP request will be retried if it fails to successfully complete during communication between the EMQX and Apache IoTDB. | 2 |
| Start Timeout | Determines the maximum time interval, in seconds, that the Connector will wait for an auto-started resource to reach a healthy state before responding to resource creation requests. This setting helps ensure that the integration does not proceed with operations until it verifies that the connected resource, such as a database instance in Apache IoTDB, is fully operational and ready to handle data transactions. | 5 |
| Buffer Pool Size | Specifies the number of buffer worker processes that will be allocated for managing data flow in egress-type bridges between EMQX and Apache IoTDB. These worker processes are responsible for temporarily storing and handling data before it is sent to the target service. This setting is particularly relevant for optimizing performance and ensuring smooth data transmission in egress (outbound) scenarios. For bridges that only deal with ingress (inbound) data flow, this option can be set to "0" as it is not applicable. | 18 |
| Request TTL | The "Request TTL" (Time To Live) configuration setting specifies the maximum duration, in seconds, that a request is considered valid once it enters the buffer. This timer starts ticking from the moment the request is buffered. If the request stays in the buffer for a period exceeding this TTL setting or if it is sent but does not receive a timely response or acknowledgment from Apache IoTDB, the request is deemed to have expired. | 45 |
| Health Check Interval | Specifies the time interval, in seconds, at which the Connector will perform automated health checks on the connection to Apache IoTDB. | 15 |
| Max Buffer Queue Size | Specifies the maximum number of bytes that can be buffered by each buffer worker in the Apache IoTDB data integration. Buffer workers temporarily store data before it is sent to IoTDB, serving as an intermediary to handle data flow more efficiently. Adjust the value according to your system's performance and data transfer requirements. | 265 |
| Query Mode | Allows you to choose asynchronous or synchronous query modes to optimize message transmission based on different requirements. In asynchronous mode, writing to IoTDB does not block the MQTT message publish process. However, this might result in clients receiving messages ahead of their arrival in IoTDB. | Async |
| Inflight Window | An "in-flight query" refers to a query that has been initiated but has not yet received a response or acknowledgment. This setting controls the maximum number of in-flight queries that can exist simultaneously when the Connector is communicating with Apache IoTDB. When the query_mode is set to async (asynchronous), the "Inflight Window" parameter gains special importance. If it is crucial for messages from the same MQTT client to be processed in strict order, you should set this value to 1. | 100 |
More Information
EMQX provides bunches of learning resources on the data integration with Apache IoTDB. Check out the following links to learn more:
Blogs: